The fragmentation problem in L2 rollups
Layer 2 rollups have scaled Ethereum by moving transaction execution off-chain, but they have inadvertently recreated the liquidity silos that plagued early cross-chain ecosystems. Each rollup operates with its own sequencer, a centralized or semi-centralized node responsible for accepting transactions, ordering them, and batching them for settlement on Layer 1. This architecture creates isolated liquidity pools where capital cannot flow freely between networks without friction.
The core issue lies in how these sequencers function. As noted by Cube Exchange, a sequencer decides transaction order and provides fast confirmations, but in many deployed systems, it remains a single operator or a tightly controlled service. When every rollup has its own sequencer, bridging between them becomes functionally identical to bridging between entirely separate blockchains. Users must wrap assets, wait for bridge finality, and navigate disparate liquidity depths, which fragments the user experience and drains capital efficiency.
This isolation forces developers to choose between security and composability. To maintain speed, they rely on private sequencers that do not share state with other networks. The result is a fragmented landscape where a trade executed on Arbitrum cannot instantly interact with liquidity on Optimism or Base without significant latency and cost. Shared sequencing aims to fix this by allowing multiple rollups to rely on a common ordering layer, effectively merging these silos into a unified execution environment.
How shared sequencers coordinate order
A standard rollup sequencer acts as a single point of authority, accepting transactions, deciding their order, and batching them for L1 settlement. This structure creates fragmentation: liquidity and MEV opportunities are trapped within individual rollup silos. A shared sequencer changes this dynamic by acting as a neutral coordinator that orders transactions across multiple rollups simultaneously. Instead of isolated order books, the shared sequencer sees the full landscape of pending activity, allowing it to construct blocks that respect cross-rollup dependencies.
The technical mechanism relies on a shared ordering layer. Rather than each rollup proposing its own independent sequence, the shared sequencer ingests transactions from various L2s, resolves conflicts, and produces a unified ordering. This ordering is then distributed to the respective rollup executors. Because the sequencer understands the global state, it can execute atomic operations that span different chains. For example, a swap between two tokens on different rollups can be settled in a single logical step, eliminating the need for risky multi-hop bridge transactions.
This coordination is essential for solving the cross-rollup MEV problem. Without a shared view, arbitrageurs exploit timing gaps between fragmented liquidity pools. A shared sequencer can internalize these opportunities or distribute them fairly, reducing the incentive for predatory front-running. The result is a more efficient market where value extraction is minimized, and users benefit from deeper, consolidated liquidity.
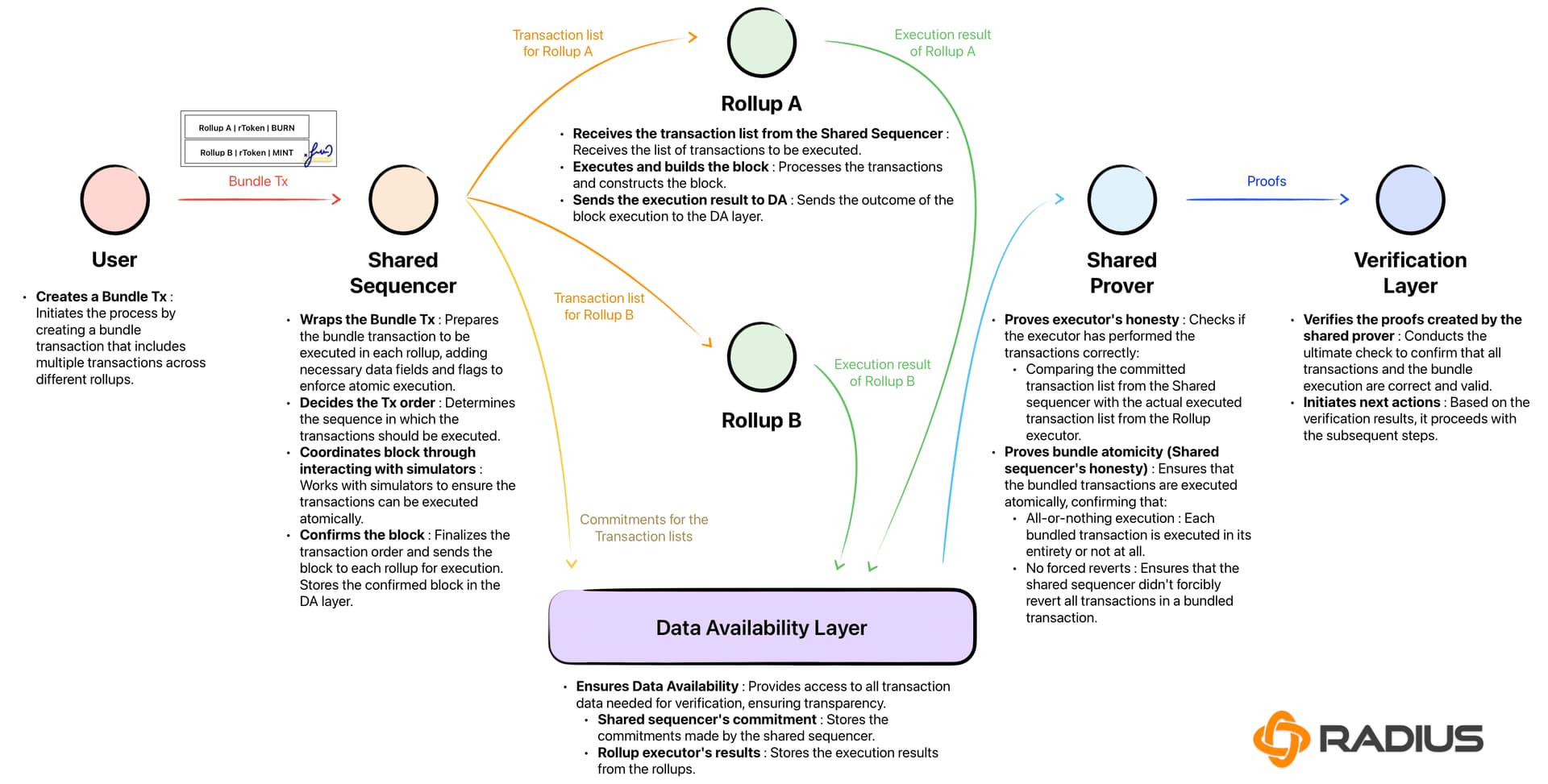
The architecture requires robust communication between the sequencer and the rollup executors. The sequencer does not execute transactions itself; it only orders them. The executors then process the ordered transactions in the agreed-upon sequence. This separation of concerns ensures that the ordering logic remains independent of the execution environment, allowing different rollups to use different VMs while still benefiting from a shared global order. This modularity is critical for maintaining flexibility in a multi-rollup ecosystem.
Cross-rollup MEV and atomic arbitrage
When liquidity is fragmented across isolated Layer 2s, value extraction opportunities multiply. Cross-rollup MEV arises when transactions on different rollups can be profitably sequenced together, creating arbitrage paths that isolated systems cannot capture efficiently. In the current landscape, a shared sequencer or "superbuilder" consolidates transactions from multiple chains, allowing for atomic execution that was previously impossible.
The mechanics of non-atomic arbitrage
Without shared sequencing, arbitrageurs face significant latency and trust barriers. A standard arbitrage strategy requires bridging assets between L2s, waiting for finality, and then executing trades on the destination chain. This non-atomic process exposes traders to front-running, bridge risks, and execution failures. The gap between L2 blocks creates a window where prices diverge, but capturing that divergence requires complex, multi-step transactions that are vulnerable to being outbid or reverted.
Shared sequencing collapses this window. By ordering transactions from different rollups in a single global sequence, it enables atomic arbitrage. A trader can submit a bundle that includes a swap on L2 A and a corresponding rebalance on L2 B, guaranteed to execute together or not at all. This eliminates the bridge risk and ensures that the arbitrage profit is captured immediately, rather than being eroded by latency or competing bots.
Reducing extraction through consolidation
The primary benefit of cross-rollup sequencing is the reduction of extractable value for predatory actors. When transactions are siloed, MEV bots can extract value from the inefficiencies between chains. By bringing these chains into a shared ordering space, the system internalizes these externalities. The arbitrage opportunities are still present, but they are captured more efficiently and transparently, often through Dutch auctions or transparent order pools, rather than through opaque front-running.
This shift transforms MEV from a predatory extraction mechanism into a market-making service. Atomic arbitrageurs provide liquidity and price alignment across ecosystems, but they do so in a way that is verifiable and fair. The result is a more efficient capital allocation across the entire L2 landscape, where prices reflect true market conditions rather than fragmentation gaps.
Trust assumptions and trade-offs
Despite the efficiency gains, shared sequencing introduces new trust assumptions. Rollups must optimistically trust the shared sequencer to create valid cross-rollup bundles. If the sequencer is malicious or censored, it could reorder transactions to extract value or exclude specific users. This centralization risk is a trade-off for the atomicity benefits. Researchers are exploring decentralized shared sequencer networks to mitigate this, but the current implementations often rely on a single operator or a tightly controlled service.
| Metric | Isolated L2s | Shared Sequencing |
|---|---|---|
| Latency | High (bridge delays) | Low (atomic execution) |
| MEV Extraction | High (predatory) | Lower (internalized) |
| Trust Model | Per-rollup trust | Shared sequencer trust |
Trust models and decentralization risks
The shift from single-operator sequencers to shared networks solves fragmentation but introduces a new set of trust assumptions. While shared sequencers—decentralized networks handling transaction ordering for multiple rollups simultaneously—reduce the risk of a single point of failure, they do not eliminate centralization entirely. The security model shifts from trusting one entity to trusting a coalition, which often remains vulnerable to collusion or coordinated downtime.
Decentralized alternatives aim to distribute this power more broadly. Projects like Interchain Security propose spinning up new rollups with decentralized sequencing by leveraging an existing set of sequencers and stake from established chains. This approach borrows security from established networks rather than relying on a new, unproven coalition, potentially offering a more robust defense against censorship or manipulation.
Another emerging model is the based rollup, where the next L1 proposer may, in collaboration with L1 searchers and builders, permissionlessly include the next rollup block as part of the L1 block. This approach tightly couples rollup sequencing with L1 consensus, reducing the window of vulnerability between transaction ordering and finality. However, it introduces complexity in block construction and may favor well-resourced actors who can participate in L1 search and build markets.
The choice between these models depends on the desired balance between efficiency and trust minimization. Shared sequencers offer speed and simplicity but require careful governance to prevent cartel-like behavior. Decentralized models like Interchain Security or based rollups offer stronger security guarantees but at the cost of increased complexity and potentially higher latency. As the ecosystem matures, we may see hybrid models that combine the best aspects of both approaches.
Real-time analytics and data aggregation
Shared sequencing transforms how analytics platforms ingest and correlate data across Layer 2 networks. When a single ordered stream serves multiple rollups, the fragmentation that previously required complex, error-prone reconciliation is eliminated. This unified ordering allows dashboards to present a single, coherent view of cross-chain activity without the latency of polling disparate sequencers.
For financial analytics, this synchronization is critical. Traders and institutions require immediate visibility into liquidity movements across ecosystems. With shared orderings, a transaction on one rollup is instantly contextualized within the broader market state, enabling faster execution decisions and more accurate risk assessments. The data pipeline becomes deterministic, reducing the "blind spots" that occur when sequencers operate in isolation.
This improvement also simplifies the architecture for data indexers. Instead of maintaining separate synchronization layers for each rollup's unique sequencer, platforms can rely on a consistent, global order. This reduces computational overhead and improves the reliability of real-time metrics, ensuring that historical data matches current market conditions precisely.
No comments yet. Be the first to share your thoughts!