Cross-rollup sequencing limits to account for
Cross-rollup sequencing orders transactions across different Layer 2 networks to ensure consistent, predictable processing. This is critical for multi-touch attribution because it determines which marketing touchpoint gets credit for a conversion when a user moves between chains.
The primary constraint is that rollups do not share a single consensus layer by default. Bridging assets between them introduces latency and potential state mismatches. Without a shared sequencing layer, you risk double-counting conversions or missing attribution signals entirely due to timing gaps.
To solve this, many projects now use shared sequencing services. These services act as a neutral third party that orders transactions before they are finalized on individual rollups. This approach reduces the overhead of launching independent sequencers for each chain while maintaining censorship resistance.
When designing your attribution stack, prioritize a sequencing layer that provides deterministic ordering. If you rely on native bridging alone, you will likely face inconsistent data. Shared sequencing ensures that the sequence of events is recorded uniformly, regardless of the underlying rollup protocol.
Evaluate cross-rollup sequencing choices that change the plan
Choosing a sequencing model requires balancing censorship resistance, finality speed, and operational overhead. Each approach shifts risk and cost between the rollup operator, the user, and the broader network. Below are the concrete factors to weigh when optimizing for multi-touch attribution in a privacy-first environment.
1. Censorship resistance vs. control
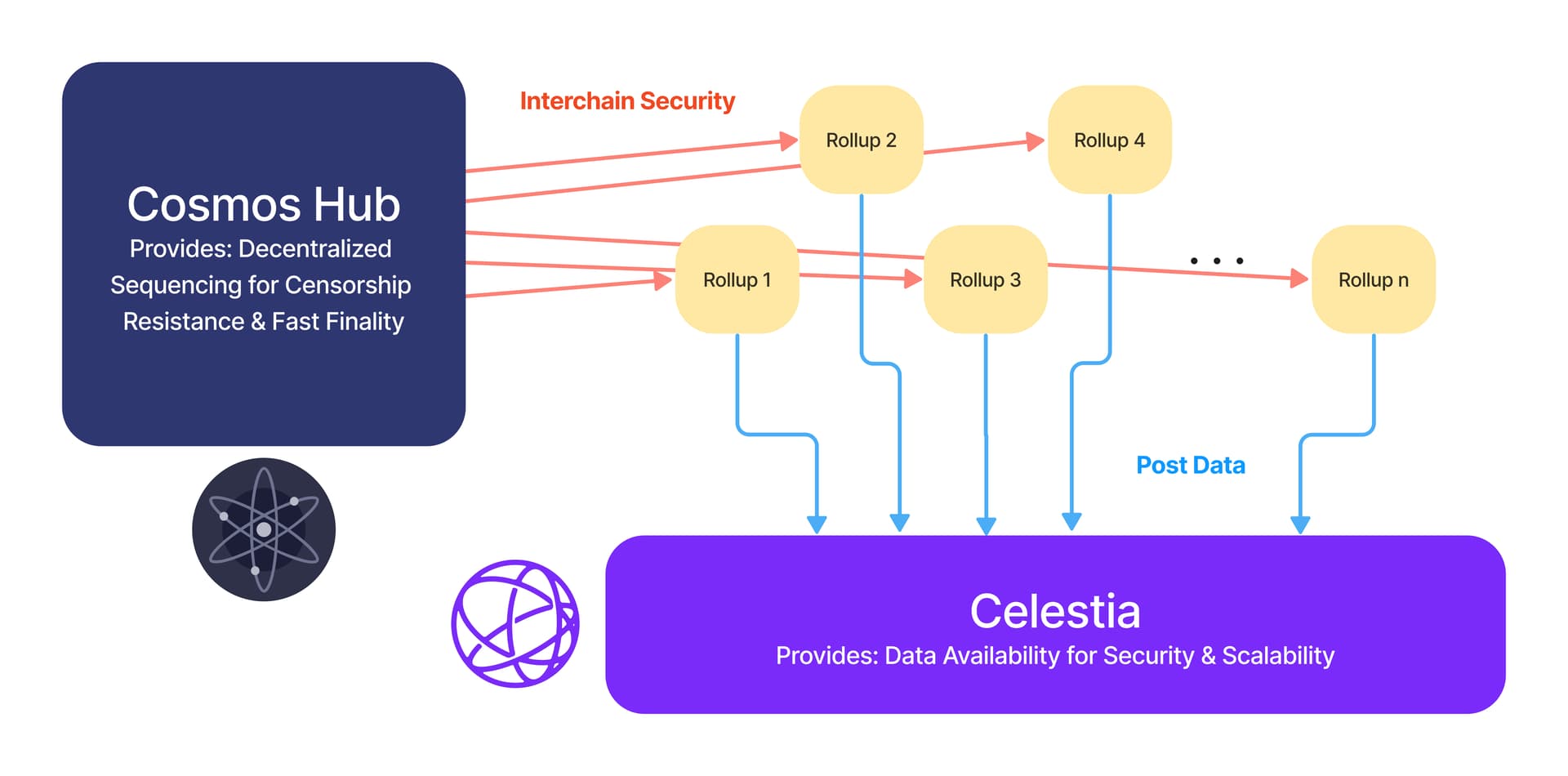
Based sequencing (L1-ordered) offers the highest censorship resistance because the Ethereum mainnet block producer validates the sequence. However, this creates a bottleneck; if L1 is congested, your rollup’s throughput suffers. Decentralized sequencing-as-a-service (e.g., via Interchain Security) distributes this risk but introduces complex validator coordination. For attribution, you must decide if losing a few seconds of finality is worth the guarantee that no single entity can drop your transaction data.
2. Finality latency and cost
Shared sequencing often reduces overhead by pooling resources, leading to lower fees and faster finality for the end-user. However, if the shared sequencer goes offline or is compromised, all dependent rollups stall. Independent sequencers offer isolation but incur higher infrastructure costs. In a privacy-first context, slower finality means longer windows for data to be exposed or manipulated before it is immutably recorded.
3. Complexity of cross-rollup bridging
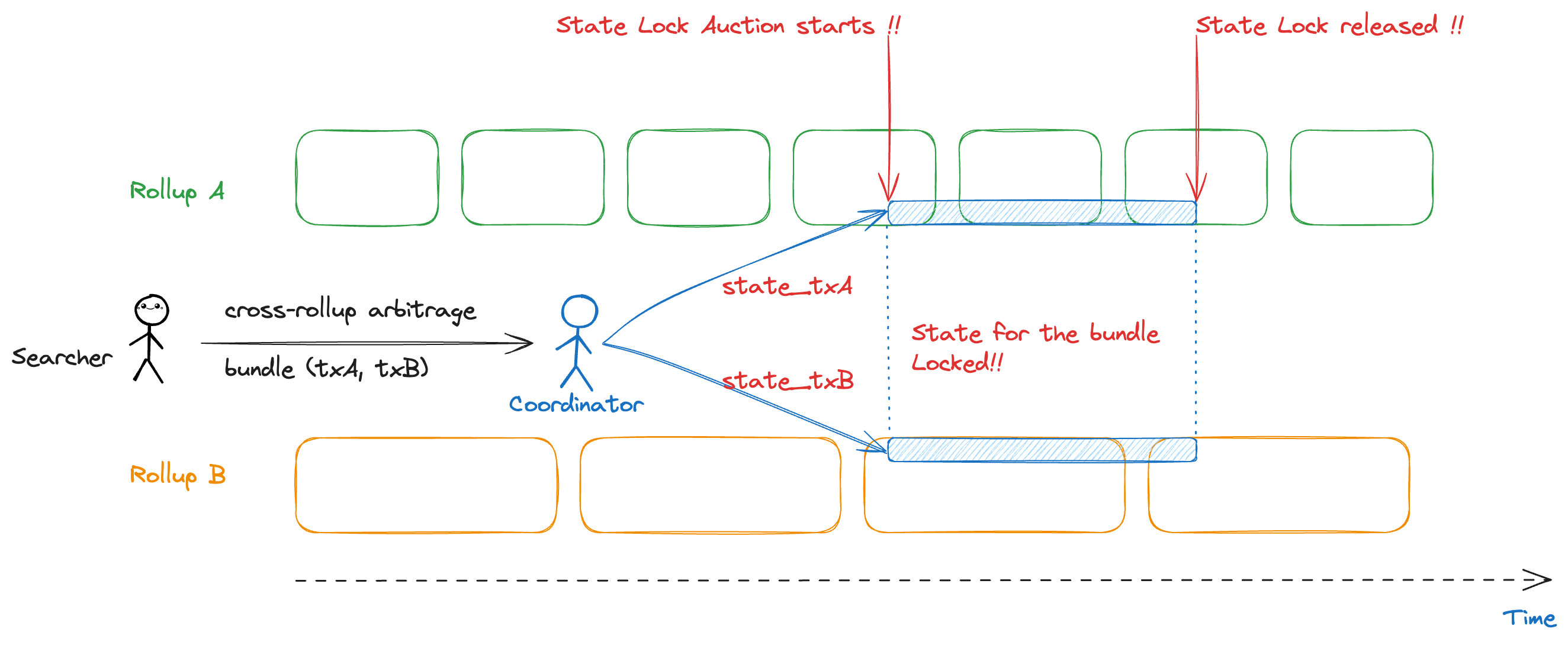
Cross-rollup bridging is not identical to cross-chain bridging. Rollups may share consensus protocols or operate in silos. The more fragmented your sequencing model, the harder it is to maintain atomicity across attribution touchpoints. Non-atomic arbitrage opportunities (MEV) can distort attribution data if transactions are reordered across rollups. Ensure your sequencing layer can guarantee order integrity across the entire user journey.
4. Operational overhead and launch speed
Decentralized sequencing incurs large overhead to launch a new rollup due to validator setup and security bonding. If your goal is rapid iteration for marketing experiments, a centralized or shared sequencer may be more practical. However, this comes at the cost of trust. You must audit the sequencer’s reputation and slasher mechanisms before relying on it for sensitive attribution data.
| Sequencing Model | Censorship Resistance | Finality Speed | Operational Cost |
|---|---|---|---|
| Based (L1-ordered) | High | Low (L1 bound) | Low |
| Shared Sequencing | Medium | High | Medium |
| Decentralized (ICS) | High | Medium | High |
| Centralized | Low | High | Low |
Community consensus on sequencing risks
The developer community highlights the tension between decentralization and practical usability. Many operators find that shared sequencing offers the best balance for most use cases, while based sequencing remains the gold standard for security-critical applications.
Proof checks and final verification
Before committing to a sequencing strategy, verify the following:
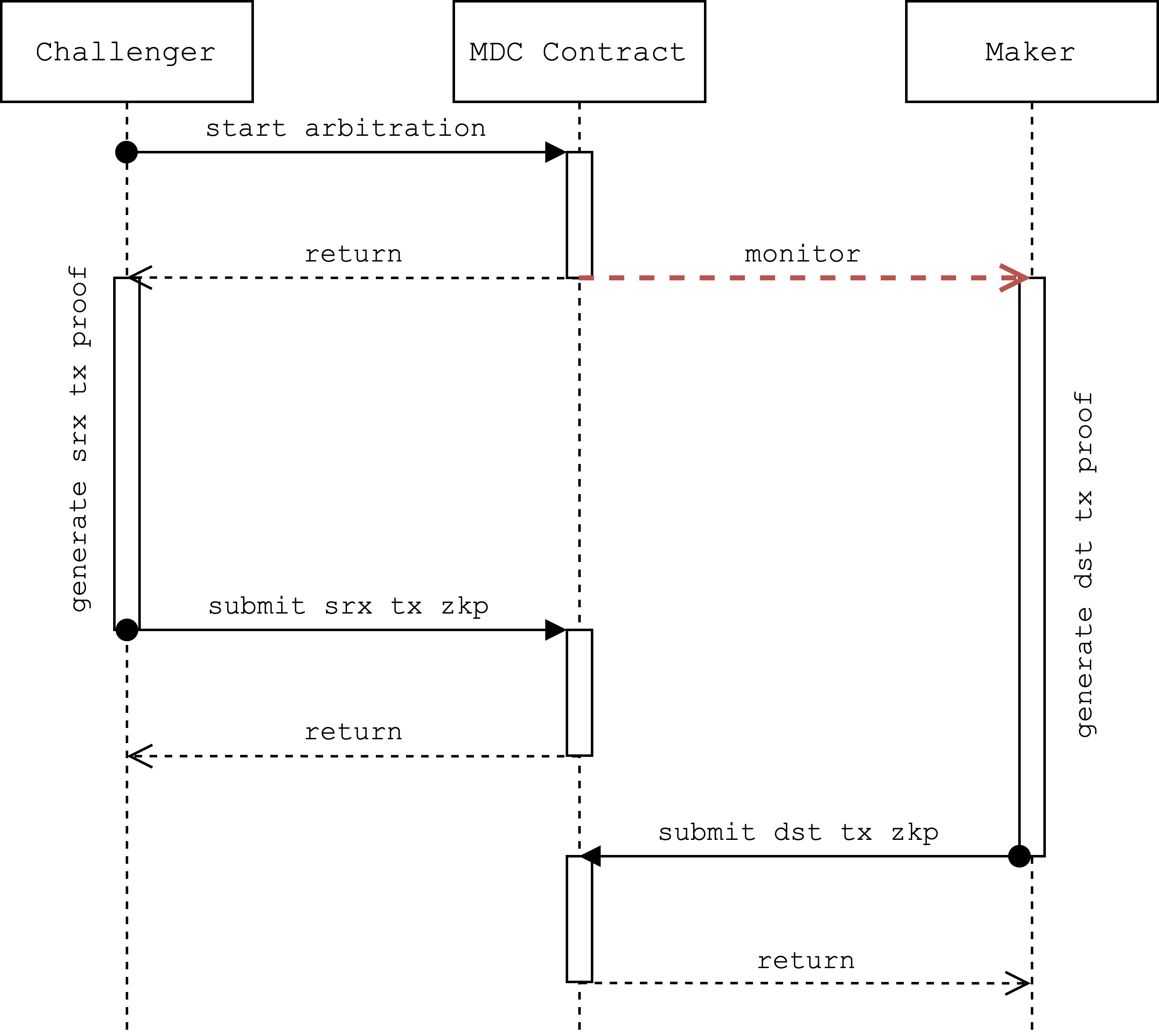
- Atomicity guarantees: Ensure the sequencer can prove order across rollups to prevent MEV distortion.
- Slasher mechanisms: Confirm that malicious sequencer behavior is penalized.
- Liveness proofs: Test how the system behaves during L1 congestion or sequencer downtime.
- Data availability: Verify that attribution data is permanently stored and accessible for long-term analysis.
"The sequencing of such rollups—based sequencing—is maximally simple and inherits L1 liveness and decentralisation." — Ethereum Research Forum
The sequencing of such rollups—based sequencing—is maximally simple and inherits L1 liveness and decentralisation.— Layer 2 Research Community
Choose the next step
Cross-Rollup Sequencing works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
Avoid the weak options
Use this section to make the Cross-Rollup Sequencing decision easier to compare in real life, not just on paper. Start with the reader's actual constraint, then separate must-have requirements from details that are merely nice to have. A practical choice should survive normal use, maintenance, timing, and budget. If a recommendation only works in an ideal situation, call that out plainly and give the reader a fallback path.
The simplest way to use this section is to write down the must-have criteria first, then compare each option against those criteria before weighing nice-to-have features.
No comments yet. Be the first to share your thoughts!