Define your atomicity requirements
Before configuring sequencers or finality bridges, you must determine whether your cross-rollup interactions require synchronous atomic execution or if asynchronous finality is sufficient. This decision dictates the entire architecture of your sequencing layer, the complexity of your smart contracts, and the user experience you will deliver.
Synchronous atomic execution ensures that transactions across multiple rollups succeed or fail together. If a transaction on Rollup A succeeds but the corresponding state update on Rollup B fails, the entire operation is reverted. This model eliminates state inconsistencies and race conditions but introduces higher latency, as the sequencer must coordinate finality across all involved chains before committing the block. This approach is necessary for use cases like atomic cross-chain swaps or complex multi-chain settlements where partial execution is unacceptable.
Asynchronous finality, by contrast, allows transactions on different rollups to complete independently. Rollup A confirms its state, and Rollup B confirms its state at different times. This model offers significantly lower latency and higher throughput but requires careful handling of potential failures. If the second rollup fails to update, you must implement a dispute mechanism or a rollback procedure. This is often sufficient for simple data availability proofs or non-critical cross-chain messaging.
To make this determination, evaluate the criticality of state consistency. If your use case involves financial assets where a mismatch between rollups could lead to loss of funds, synchronous atomic execution is the only safe path. For data synchronization or non-critical interactions, asynchronous finality reduces complexity and cost. Refer to EthResearch discussions on cross-rollup synchronous atomic execution for deeper technical context on implementing shared sequencing layers.
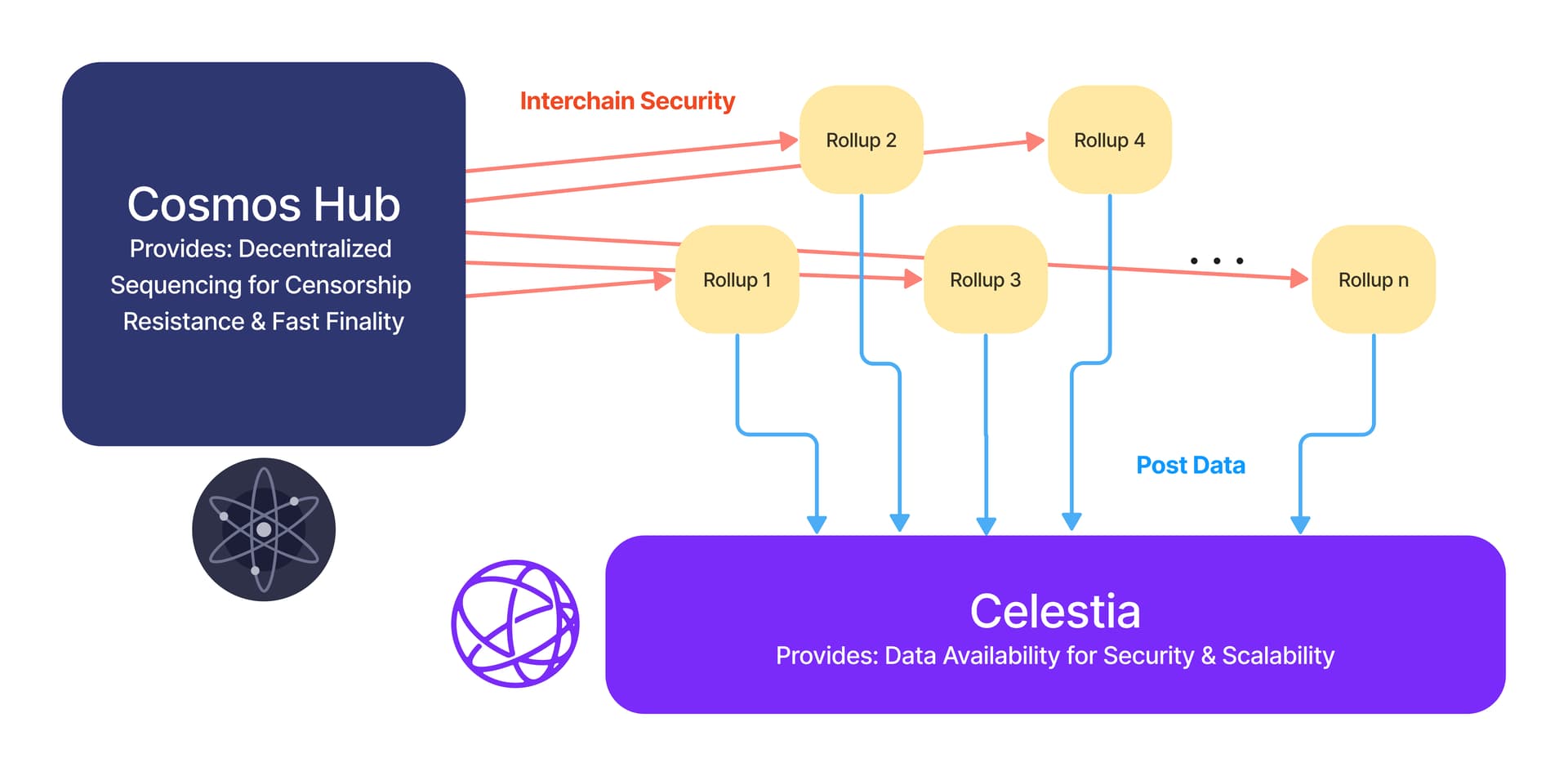
Select a shared sequencing infrastructure
Choosing the right shared sequencing layer determines how rollups communicate. The decision balances latency, decentralization guarantees, and operational control. You can route transactions through centralized providers, decentralized networks like Celestia, or build a custom shared layer.
Centralized Shared Sequencers
Centralized providers offer the lowest latency and simplest integration. They act as a single point of order for multiple rollups, ensuring transactions are sequenced deterministically before being posted to L1. This approach is ideal for teams prioritizing speed and ease of deployment over censorship resistance.
Espresso Systems is a primary example. Their architecture separates sequencing from publishing, allowing rollups to maintain their own data availability while relying on Espresso for ordering. This model is currently the most mature for high-throughput applications requiring fast finality. HackMD documentation details the technical benefits of this defragmentation approach.
Decentralized Networks
Decentralized sequencing distributes trust across a network of validators. This model prevents any single entity from censoring transactions or manipulating order. It is the preferred choice for projects requiring strong censorship resistance and alignment with Ethereum's decentralized ethos.
Celestia offers decentralized sequencing as a service via Interchain Security. By leveraging an existing set of sequencers and stake, you can spin up a new rollup with decentralized sequencing capabilities. This reduces the operational burden of managing your own sequencer set while maintaining security guarantees. Celestia Forum outlines the technical implementation.
Custom Shared Layers
Building a custom shared layer gives you full control over the sequencing logic, data availability, and settlement rules. This approach is complex and resource-intensive but necessary for projects with unique compliance or performance requirements. It requires significant engineering effort to ensure liveness and safety.
Compose Network's Shared Publisher architecture presents a novel approach to cross-rollup synchronous composability. It separates sequencing from publishing, allowing for flexible integration with various data availability layers. This model is suitable for teams willing to invest in infrastructure to achieve specific composability goals. Compose Network provides an overview of this architecture.
Comparison of Options
The following table compares the key attributes of each shared sequencing infrastructure. Use this to guide your technical decision based on your project's priorities.
| Provider | Latency | Decentralization | Setup Complexity |
|---|---|---|---|
| Centralized (e.g., Espresso) | Low | Low | Low |
| Decentralized (e.g., Celestia) | Medium | High | Medium |
| Custom Shared Layer | Variable | Custom | High |
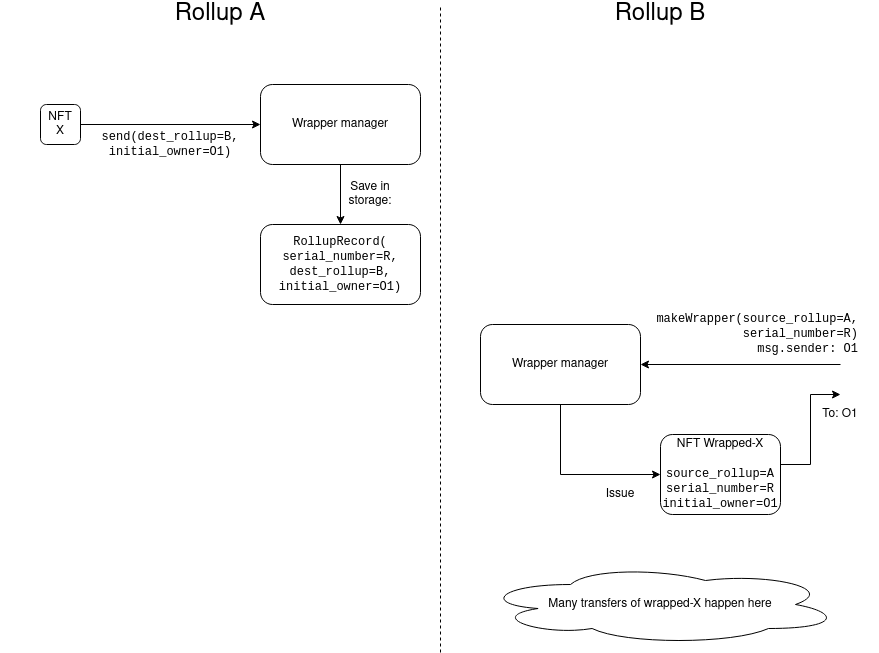
Configure transaction ordering logic
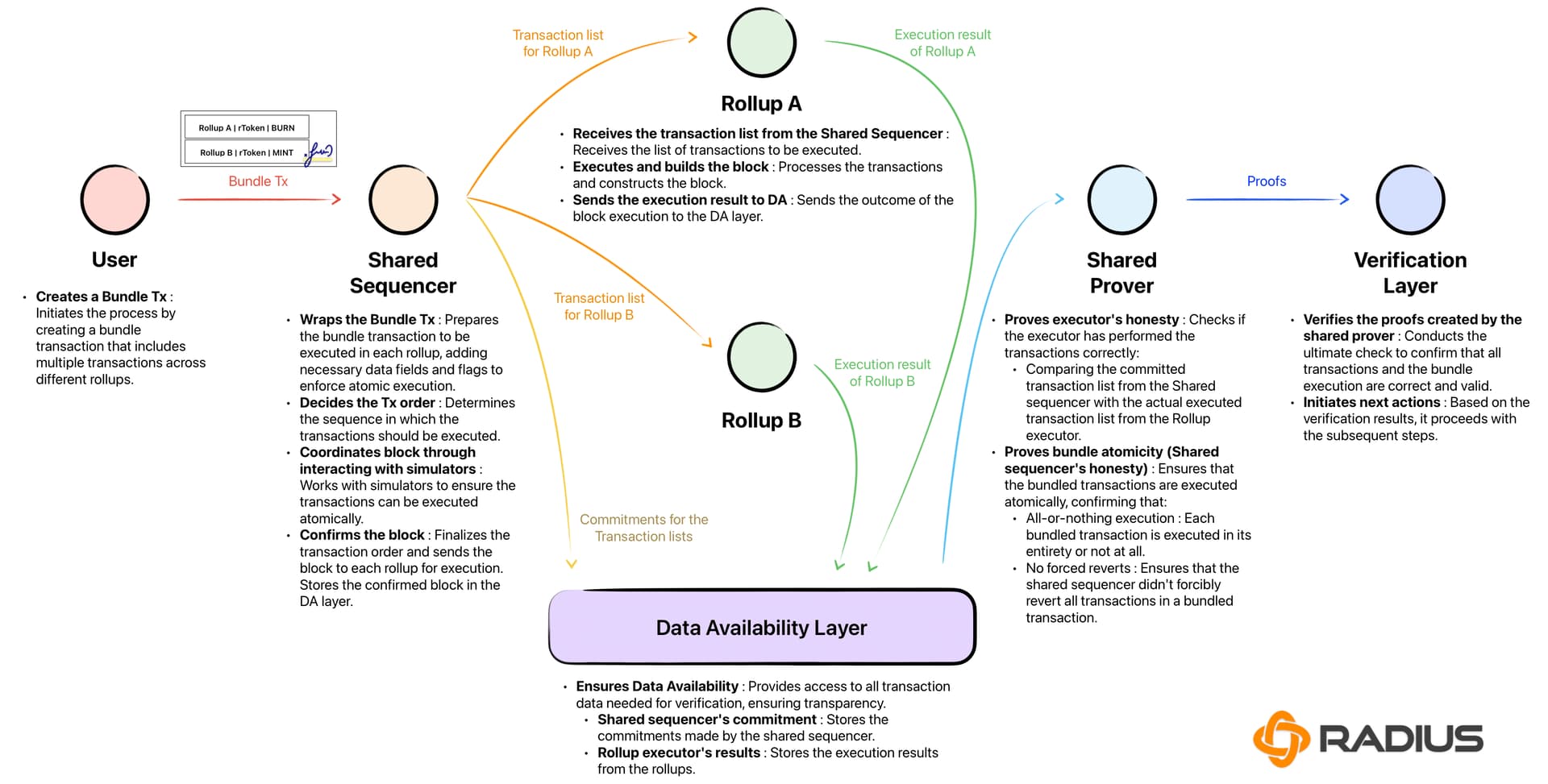
Setting up the sequencing layer requires defining how transactions are prioritized across different rollups. The goal is to establish a shared endpoint that accepts payloads and applies a consistent ordering rule. Without this, cross-rollup transactions become unpredictable, and fee markets fail to differentiate between transaction types effectively.
1. Define the shared sequencer endpoint
Start by configuring the network endpoint that all rollups will use for sequencing. This endpoint acts as the central hub where transactions from L2A and L2B are received before being ordered. Ensure the endpoint supports the standard payload format used by your specific rollup implementations. This setup creates the foundation for any cross-rollup logic.
Configure the network endpoint that all rollups will use for sequencing. This endpoint acts as the central hub where transactions from L2A and L2B are received before being ordered. Ensure the endpoint supports the standard payload format used by your specific rollup implementations. This setup creates the foundation for any cross-rollup logic.
Define how fees are calculated and prioritized. The sequencing layer must distinguish between transaction types to prevent congestion. Adjust gas limits and priority fee multipliers to ensure high-value cross-rollup transactions are processed before standard ones. This differentiation is critical for maintaining order integrity.
Set up the internal data structures that hold transactions before they are sequenced. Use a priority queue that sorts transactions based on the fee parameters defined in the previous step. This ensures that the sequencer always picks the highest-value transaction next, maintaining the intended order across rollups.
Test the endpoint with sample payloads from both rollups. Verify that the shared sequencer can parse and order transactions from different rollup structures without errors. This validation step confirms that your configuration supports the cross-rollup logic you are building.
2. Test the sequencing logic
Once the configuration is complete, run a series of test transactions. Send mixed transactions from both rollups to the shared endpoint. Monitor the ordering to ensure that the priority queue and fee market parameters are working as expected. Adjust the parameters if the ordering does not match your requirements.
Mitigate Cross-Rollup MEV Risks
Shared sequencing creates a single pool for transactions from multiple rollups, which introduces new vectors for Maximal Extractable Value (MEV). Without proper safeguards, a sequencer can reorder, censor, or sandwich transactions across rollup boundaries to extract value from users. This risk is higher than in isolated rollups because the visibility of cross-rollup intents allows for more complex arbitrage and front-running strategies.
To protect user transactions, implement encryption or randomized ordering for sensitive cross-rollup data. Encryption ensures that the sequencer cannot inspect transaction contents before inclusion, neutralizing front-running. Alternatively, randomized ordering prevents the sequencer from exploiting deterministic patterns in transaction arrival times. These methods force the sequencer to process transactions without the ability to selectively reorder them for profit.
Additionally, integrate MEV-resistant ordering protocols like Fair Sequencing Services (FSS). FSS uses cryptographic techniques to ensure that transactions are ordered fairly, regardless of their arrival time at the sequencer. This approach reduces the incentive for sequencers to engage in predatory practices. By adopting these measures, you can maintain the efficiency of shared sequencing while preserving user trust and security.
Verify synchronous execution proofs
Validation requires confirming that the state transitions across all involved rollups are identical and atomic. You cannot rely on individual chain receipts alone, as a successful transaction on one rollup does not guarantee the corresponding action completed on the other. The verification process hinges on the shared validity proof generated during the sequencing phase.
Start by extracting the execution proof from the shared sequencer’s output. This proof contains the cryptographic commitments for every state change across the participating chains. You must then run a verification script against each rollup’s verifier contract or local node. The script checks that the Merkle root updates on Chain A match the expected state derived from the proof, and that Chain B’s state root aligns with the same input set.
If the proofs diverge, the transaction failed atomic execution. In this case, the sequencer likely dropped the batch or one rollup rejected the validity proof due to a state mismatch. You must then inspect the shared sequencer logs to identify which chain caused the failure. Only when all verifiers return a valid status can you consider the cross-rollup transaction settled.
Cross-rollup sequencing checklist
-
Verify shared sequencer connectivity and latency thresholds
-
Test atomic execution across two distinct rollup environments
-
Validate state root synchronization for cross-rollup transactions
-
Confirm MEV protection mechanisms are active
-
Run end-to-end failure recovery simulations
Common cross-rollup sequencing: what to check next
Cross-rollup sequencing introduces specific technical hurdles regarding latency, atomicity, and MEV. The following questions address the most frequent implementation challenges encountered in 2026.
No comments yet. Be the first to share your thoughts!